
🚀 TurboQuant vs 기존 AI 압축 기술
— “왜 이 기술이 게임체인저인가?”
1️⃣ 기존 방식: 단순한 정밀도 축소 (정보를 버린다)


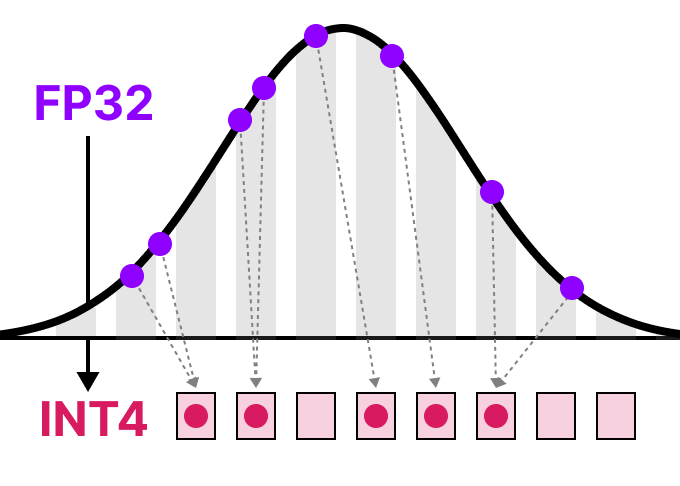

기존 AI 모델 최적화는 매우 단순한 방식이다.
👉 숫자의 정밀도를 줄인다
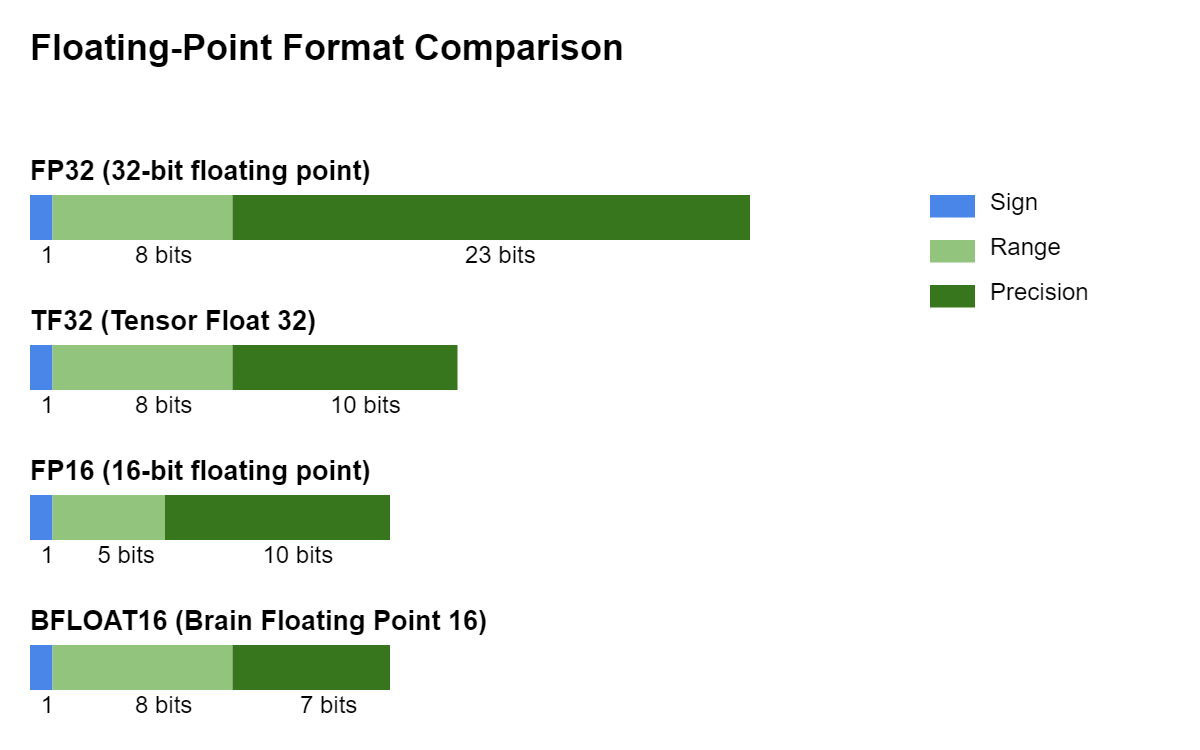
- FP32 → INT8 → INT4
- 숫자를 반올림해서 저장
✔ 문제
- 중요한 값까지 같이 손실됨
- 특히 outlier 값에서 성능 급락
- 긴 문맥에서 오류 누적
👉 핵심 구조
데이터 → 정밀도 축소 → 정보 손실 → 성능 저하
2️⃣ TurboQuant: 구조 자체를 바꾼다 (정보를 “보존”한다)


Google Research가 만든 TurboQuant는 접근 방식이 완전히 다르다.
👉 단순히 “줄이는 기술”이 아니라
👉 “압축을 잘 되게 만드는 기술”
핵심 3단계
① 데이터 재배열 (Random Rotation)
- 데이터를 압축하기 쉬운 형태로 변환
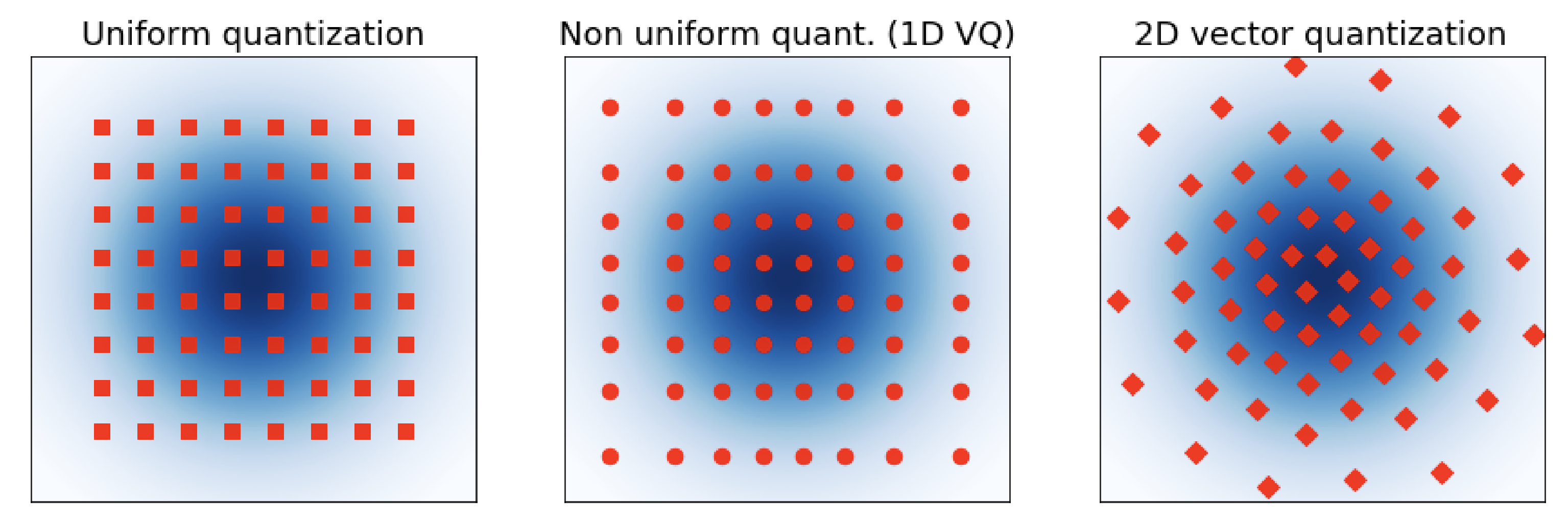
② 벡터 단위 압축 (Vector Quantization)
- 숫자 하나가 아니라
👉 “패턴 단위”로 압축
③ 오류 보정 (Residual Correction)
- 남은 오차를 추가 비트로 보정
👉 핵심 구조
데이터 → 구조 변환 → 패턴 압축 → 오류 보정 → 정보 유지
3️⃣ 한눈에 비교 (핵심 그림)
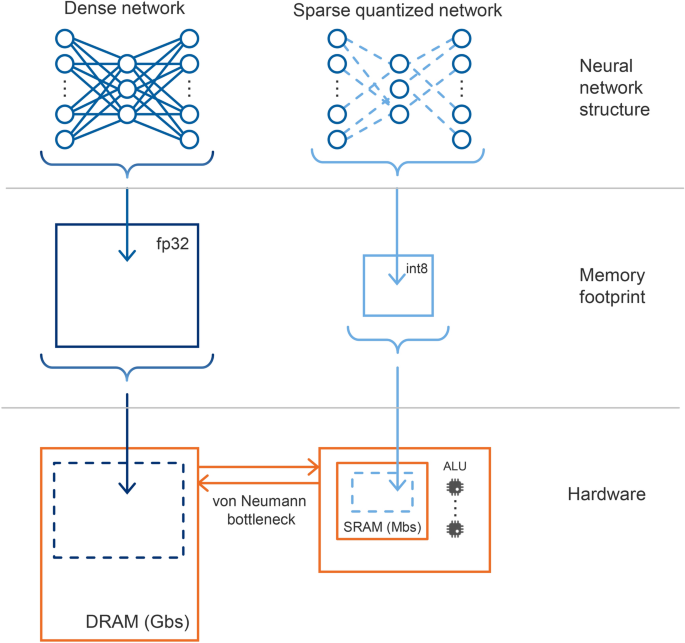

구분기존 QuantizationTurboQuant
| 방식 | 단순 축소 | 구조 기반 압축 |
| 단위 | scalar | vector |
| 정확도 | 손실 발생 | 거의 유지 |
| 처리 | 단순 | 복합 알고리즘 |
| 결과 | 빠르지만 부정확 | 빠르고 정확 |
4️⃣ 왜 차이가 이렇게 클까? (엔지니어 관점 핵심)
이 차이는 사실 데이터를 보는 관점 차이다.
기존 방식
👉 “숫자 하나씩 본다”
[0.123] → [0.12]
[0.987] → [0.99]
→ 의미가 깨짐
TurboQuant
👉 “패턴으로 본다”
[0.123, 0.987, 0.456]
→ 하나의 벡터로 압축
→ 구조 유지
→ 의미 유지
5️⃣ 결과: 왜 산업이 흔들리는가
이 차이 하나로 결과는 완전히 달라진다.
기존
- 메모리 많이 필요
- 긴 문맥 처리 어려움
- 비용 증가
TurboQuant
- 메모리 최대 6배 감소
- 속도 최대 8배 향상
- 긴 context 처리 가능
👉 한 줄 요약
“정보를 버리느냐 vs 구조를 살리느냐의 차이”
6️⃣ Insight
이건 단순한 AI 기술이 아니다.
🔥 진짜 의미
👉 AI 경쟁의 기준이 바뀐다
| 과거 | 미래 |
| 모델 크기 | 효율 |
| GPU 수 | 메모리 활용 |
| 학습 데이터 | inference 최적화 |
특히 반도체/자동화 관점에서는:
👉 “더 좋은 모델”보다
👉 “같은 모델을 얼마나 싸게 돌리느냐”가 핵심
🎯 결론
👉 TurboQuant는
“압축 기술”이 아니라 “AI 구조를 바꾸는 기술”
🚀 TurboQuant vs Traditional Quantization
— Why This Changes the Game in AI Efficiency
1️⃣ Traditional Quantization: “Reduce Precision, Lose Information”


Traditional AI optimization is simple:
👉 Reduce numerical precision
- FP32 → INT8 → INT4
- Values are rounded and compressed
✔ The Problem
- Important signals are lost
- Outliers break model performance
- Errors accumulate in long-context inference
👉 Core mechanism
Data → Precision Reduction → Information Loss → Performance Drop
2️⃣ TurboQuant: “Restructure Before Compressing”
Developed by Google Research, TurboQuant takes a fundamentally different approach:
👉 Not just compression
👉 Compression with structure preservation
Core 3 Steps
① Random Rotation
- Transform data into a compression-friendly structure
② Vector Quantization
- Compress patterns, not individual numbers
③ Residual Correction
- Recover lost details with minimal extra bits
👉 Core mechanism
Data → Structural Transformation → Pattern Compression → Error Correction → Information Preserved
3️⃣ Side-by-Side Comparison
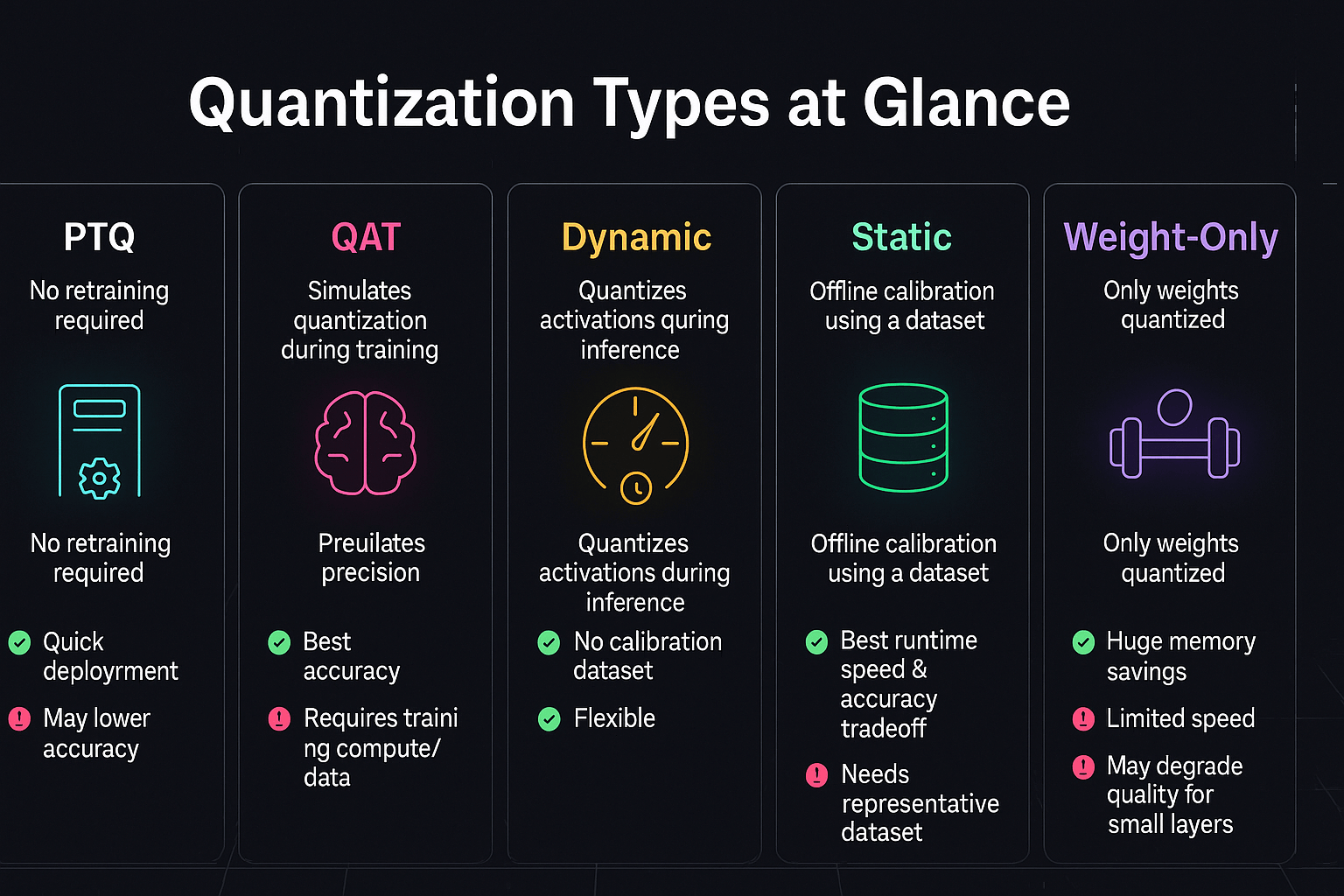
CategoryTraditional QuantizationTurboQuant
| Method | Scalar reduction | Structure-aware compression |
| Unit | Individual values | Vectors (patterns) |
| Accuracy | Degrades | Near-lossless |
| Complexity | Low | High |
| Result | Faster but weaker | Faster and accurate |
4️⃣ The Real Difference (Engineer’s Insight)
This is not just a better algorithm.
👉 It’s a different way of “seeing data.”
Traditional Approach
👉 Treat numbers independently
[0.123] → [0.12]
[0.987] → [0.99]
→ Meaning gets distorted
TurboQuant Approach
👉 Treat data as structured patterns
[0.123, 0.987, 0.456]
→ Compressed as a vector
→ Structure preserved
→ Meaning remains intact
5️⃣ Why It Matters
This difference leads to massive real-world impact:
- Up to 6× memory reduction
- Up to 8× faster attention computation
- Enables long-context AI (100K+ tokens)
👉 One-line summary
“Not throwing information away — but compressing it intelligently.”
6️⃣ Industry Implications
This is bigger than optimization.
🔥 Shift in AI Competition
BeforeAfter
| Bigger models | More efficient models |
| More GPUs | Better memory utilization |
| Training power | Inference efficiency |
What Changes Next?
- AI becomes cheaper to deploy
- Edge AI becomes more realistic
- Memory bottlenecks become less critical
🎯 Final Takeaway
👉 TurboQuant is not just a compression technique
👉 It is a fundamental shift in how AI systems scale efficiently
'T — Tech & Trends' 카테고리의 다른 글
| [digital twin-5] 디지털 트윈 시장 어디까지 성장할까? 핵심 기업과 투자 포인트 (0) | 2026.03.23 |
|---|---|
| [digital twin-4] 디지털 트윈은 어디에 쓰일까? 제조·항공·반도체 실제 사례 총정리 (0) | 2026.03.23 |
| [digital twin-3] 디지털 트윈 시스템 구조 완전 해부: 센서부터 시뮬레이션까지 (0) | 2026.03.22 |
| [digital twin-2] 디지털 트윈은 어떻게 구현할까? 기계공학 필수 이론 총정리 (0) | 2026.03.21 |
| [digital twin-1] 디지털 트윈이 뭐길래? 기계공학이 바꾸는 ‘가상 설계’의 시대 (0) | 2026.03.21 |




댓글